Compreensão do efeito do quórum sobre o comportamento do sistema
Um servidor de quórum em
No entanto, se ocorrem falhas mais catastróficas (por exemplo, a perda de todos os caminhos de rede possíveis), o sistema ztC Edge tentará determinar o estado geral do sistema inteiro. Em seguida, o sistema toma as medidas necessárias para proteger a integridade das MVs convidadas.
Os exemplos a seguir mostram o processo do sistema durante uma falha catastrófica.
Exemplo 1: Um sistema sem um servidor de quórum apresenta uma situação de cérebro dividido
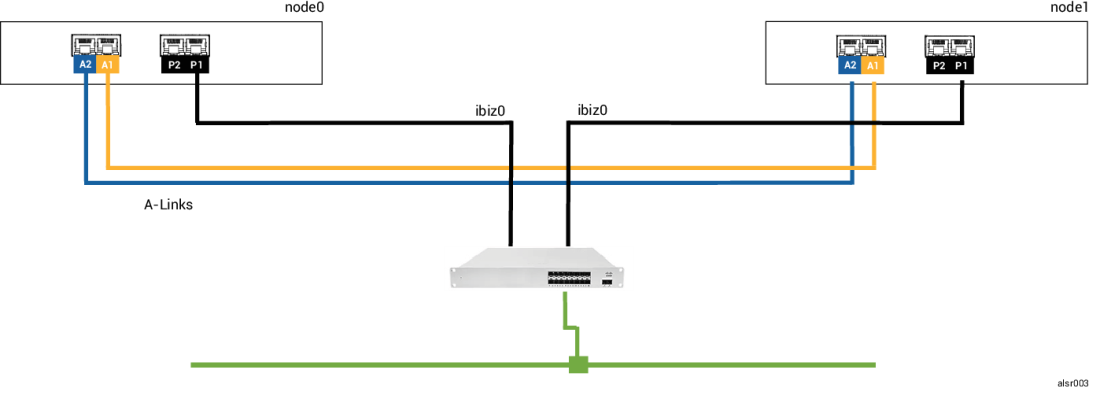
Neste exemplo ALSR, o sistema ztC Edge inclui o node0 e o node1, mas não contém um servidor de quórum. A operação está normal, nenhuma falha foi detectada no momento. Os dois nós informam seus respectivos estados e disponibilidade por meio das conexões A-Link, como o fazem durante a operação normal (sem falhas). A seguinte ilustração mostra as conexões normais.
Uma falha catastrófica
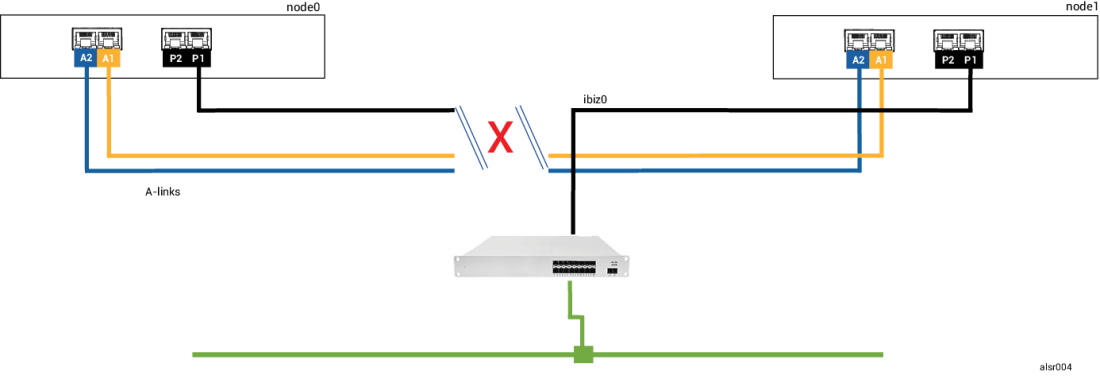
Um operador de empilhadeira descuidado arromba a parede, cortando todas as conexões de rede (corporativas e A-Links), mas mantendo a energia disponível e o sistema em funcionamento. A seguinte ilustração mostra a condição da falha.
Processamento de falhas
Os dois nós processam a falha da seguinte forma:
- Node0 — o AX no node0 detecta a perda de ambas A-Links, assim como de todos os outros caminhos de rede. Como o node0 AX não pode mais detectar a presença do seu parceiro, ele se torna inativo e coloca em execução a MV convidada. O aplicativo que está na MV convidada continua a funcionar, talvez com capacidade limitada devido à perda de rede.
- Node1 — o AX no node1 também detecta a perda de ambas A-Links, mas a ibiz0 permanece disponível. Como o seu parceiro não responde às mensagens na ibiz0, o node1 AX agora está ativo. O aplicativo que está na MV convidada continua a funcionar, talvez por não perceber qualquer problema com o sistema.
Sob a perspectiva de um cliente do aplicativo ou de um observador externo, as duas MVs convidadas estão ativas e geram mensagens de rede com o mesmo endereço do remetente. As duas MVs convidadas geram dados e veem diferentes quantidades de falhas de comunicação. Os estados das MVs convidadas se tornam mais divergentes ao longo do tempo.
Recuperação e reparo
Após algum tempo, a conectividade de rede é restaurada: a parede é reparada e os cabos de rede são substituídos.
Quando cada AX do par de AX percebe que o seu parceiro está novamente online, o par AX com as regras do gerenciador de falhas escolhe o AX que continua ativo. A escolha é imprevisível e não abrange considerações sobre qual desempenho de nó foi mais preciso durante a situação de cérebro dividido.
Os dados gerados pelo nó que agora está em espera são substituídos pela ressincronização do nó ativo e, portanto, os dados no nó que agora está em espera são perdidos de forma permanente.
Após uma situação de cérebro dividido, o sistema necessita de vários minutos para se ressincronizar, dependendo do volume de atividade do disco que precisa ser enviado para o nó em espera. Se diversas MVs estiverem funcionando com diferentes nós ativos, o tráfego de sincronização poderá ocorrer em ambas direções.
Exemplo 2: Um sistema ALSR com um servidor de quórum evita uma situação de cérebro dividido
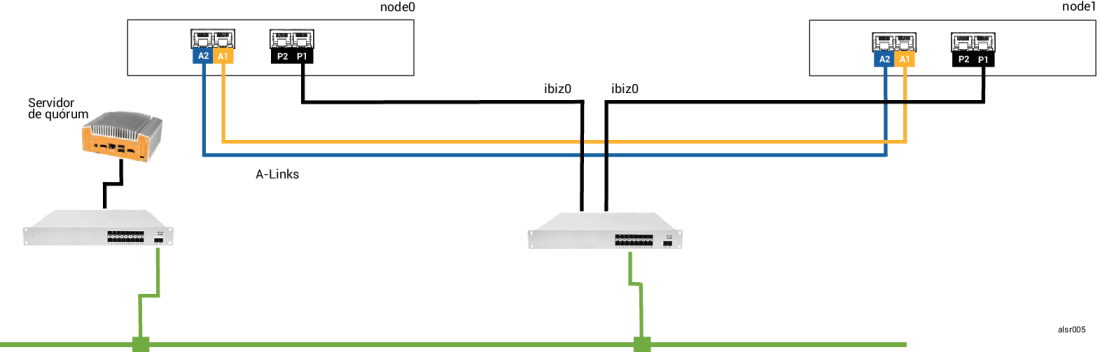
Neste exemplo ALSR, o sistema ztC Edge contém o node0 e o node1 com conexões idênticas às do sistema no Exemplo 1. Além disso, o sistema no Exemplo 2 inclui um servidor de quórum. A seguinte ilustração mostra essas conexões.
Uma falha catastrófica
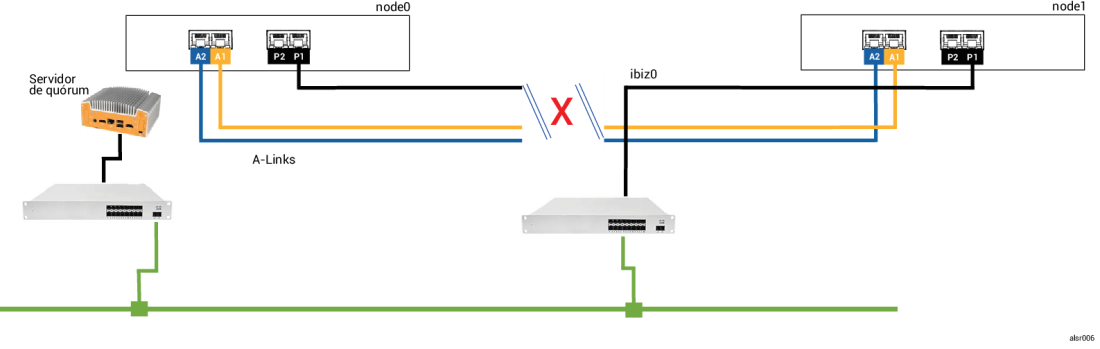
Aquele operador de empilhadeira descuidado arromba novamente a parede, cortando todas as conexões de rede (corporativas e A-Links), mas mantendo a energia disponível e o sistema em funcionamento. A seguinte ilustração mostra a condição da falha.
Processamento de falhas
Os dois nós processam a falha da seguinte forma:
- Node0 — o AX no node0 detecta a perda de ambas A-Links, assim como de todos os outros caminhos de rede. Como o node0 AX não pode mais detectar a presença do seu parceiro, ele tenta se comunicar com o servidor de quórum. Nesse caso, o servidor de quórum também está indisponível. Portanto, o node0 AX decide se encerrar. O encerramento não é um desligamento normal do Windows, mas uma interrupção abrupta, o que faz com que o aplicativo na MV convidada pare.
- Node1 — o AX no node1 também detecta a perda de ambas A-Links, mas a ibiz0 permanece disponível. O node1 AX tenta se comunicar com o servidor de quórum, que responde, e assim o node1 permanece ativo. O aplicativo que está na MV convidada continua a funcionar, talvez por não perceber qualquer problema com o sistema.
Sob a perspectiva de um cliente do aplicativo ou de um observador externo, a MV convidada no node1 permanece ativa e gera dados enquanto a MV no node0 é encerrada. Não há nenhuma situação de cérebro dividido.
Recuperação e reparo
Após algum tempo, a conectividade de rede é restaurada: a parede é reparada e os cabos de rede são substituídos.
Quando o node1 AX percebe que o seu parceiro está novamente online, o node0 AX é colocado em espera. Devido ao node0 não estar anteriormente em funcionamento, a sincronização de dados começa do node1 para o node0.
Como não ocorreu uma situação de cérebro dividido, não houve perda de dados.
O sistema necessita de alguns minutos para se ressincronizar, dependendo do volume de atividade do disco que precisa ser enviado para o nó em espera.
Exemplo 2, modificado: O servidor de quórum está inacessível durante a falha catastrófica
Em
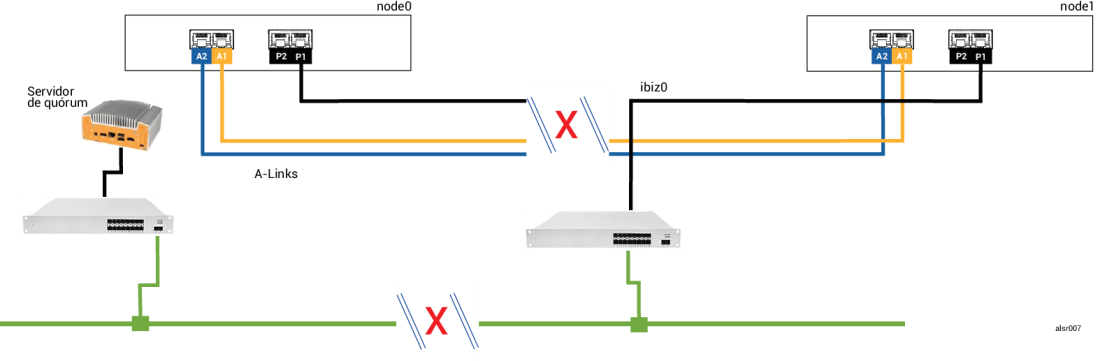
O processamento de falhas é semelhante ao adotado no Exemplo 2, com uma importante diferença para o node1:
Nesse caso, a MV convidada é encerrada no node0 e no node1, evitando que ocorra uma situação de cérebro dividido. A desvantagem é que a MV convidada fica indisponível até que a conexão com o node0 ou com o servidor de quórum seja restaurada.
Nesse caso, determine qual nó não será utilizado e desligue-o. Em seguida, force a inicialização do nó que deverá entrar em operação e, depois, faça o mesmo com a MV. Para obter informações sobre como encerrar uma MV e reiniciá-la, consulte Gerenciamento da operação de uma máquina virtual.)
Exemplo 2, modificado: O servidor de quórum está inacessível, sem nenhuma falha catastrófica
Em algumas situações, o servidor de quórum pode estar inacessível mesmo que não ocorra uma falha física catastrófica. Um exemplo dessa situação é quando o computador de quórum é reinicializado para manutenção de rotina, como aplicar uma correção no sistema operacional. Nessas situações, o AX detecta que o serviço de quórum não está respondendo e, portanto, suspende o tráfego de sincronização até que a conexão com o servidor de quórum seja restaurada. A MV convidada continua funcionando no nó que estava ativo quando a conexão foi perdida. No entanto, a MV convidada não se move para o nó em espera porque podem ocorrer mais falhas. Depois que o serviço de quórum é restaurado, o AX retoma a sincronização e o processamento normal de falhas, desde que a conexão com o servidor de quórum seja mantida.
Recuperação após uma queda de energia
Se o sistema for reiniciado após uma queda de energia ou um encerramento do sistema, o ztC Edge aguardará indefinidamente que o seu parceiro inicialize e responda, antes de iniciar qualquer MV convidada. Se o AX que estava anteriormente ativo puder se comunicar com o servidor de quórum, o AX iniciará a MV convidada imediatamente, sem esperar que o nó parceiro seja inicializado. Se o AX que estava anteriormente em espera inicializar primeiro, ele aguardará o nó parceiro.
Se o sistema receber uma resposta do nó parceiro ou do servidor de quórum, a operação normal será retomada e a MV se iniciará, sujeita às mesmas regras do gerenciador de falhas que se aplicam a outros casos.
Se o sistema não receber uma resposta do servidor de quórum ou não tiver esse recurso, uma pessoa deverá forçar a inicialização de uma MV convidada, o que substitui qualquer decisão feita pelo AX ou pelo gerenciador de falhas. Deve-se garantir que duas pessoas não forcem a inicialização da mesma MV convidada no node0 e no node1. Esse procedimento pode causar inadvertidamente uma situação de cérebro dividido de cérebro dividido.